大家好,我是長風青雲。今天是第二十七天,我已經分類好我們的影片了~
那我們先來規劃一下我們的html,再把我們的影片和文案展示在上面~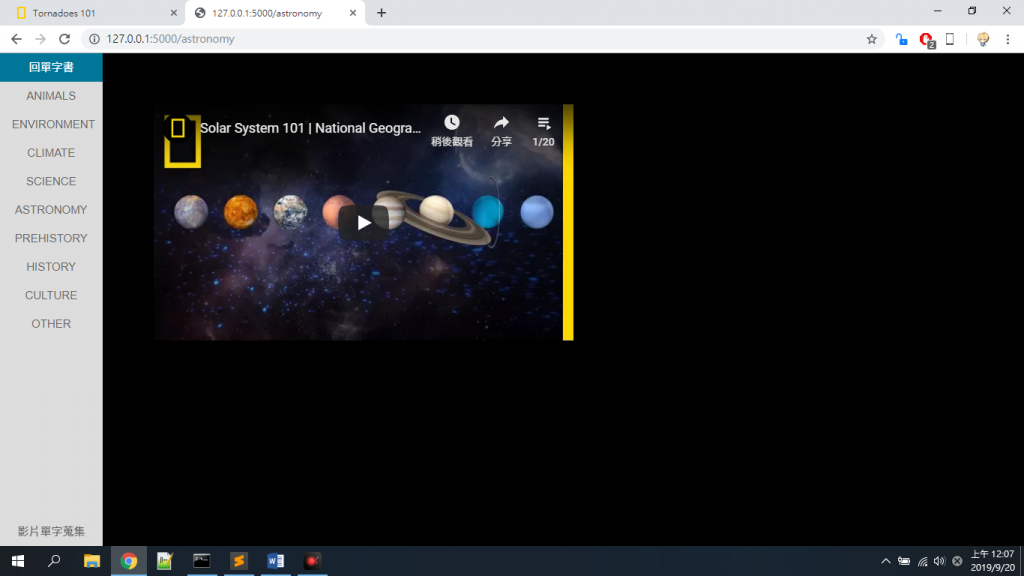
拿出以前的規劃,當時影片是先在youtube上面整理好成清單讓人可以直接這樣使用。右方是我們的文字。
但是這樣子做右方的文字並不會與我們所觀看的影片而有所不同,所以才會變成用crawl的方式。
好,接下來,回到我們的影片和文案部分。
親愛的各位,當我今天實際爬取影片真實位置時遇到一個大問題。
我其實是依照以往的使用Beautifulsoup進行爬取,卻發現怎麼也爬不到我的video。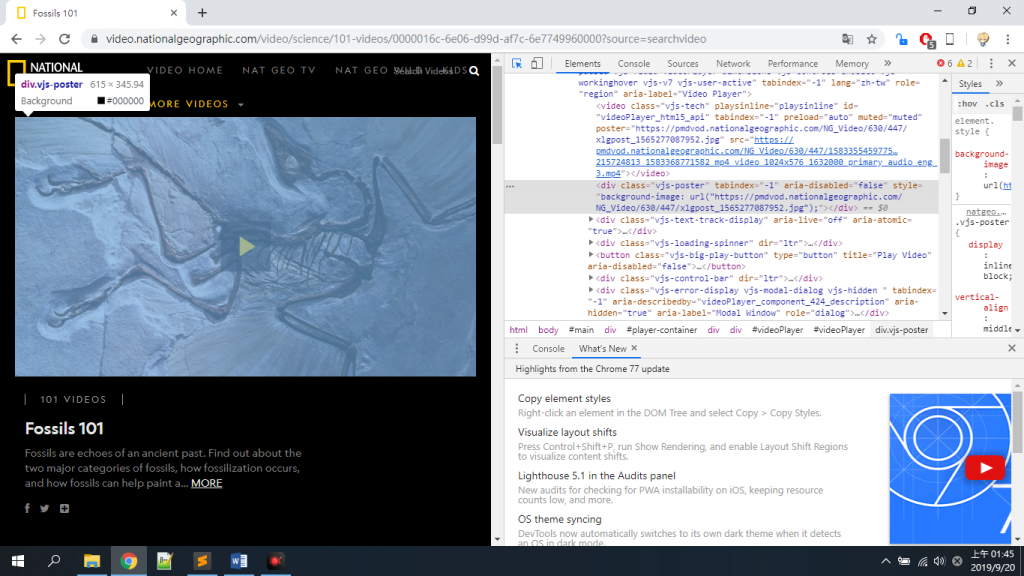
「我明明就看到<video>了怎麼就是爬不出來?!」
這個網頁他是使用js渲染出來的,開啟時你還要等待js渲染出來才可以爬取。
但我們的crawler他是直接把他第一時間還未等待js的html給抓下來,所以抓下來時並沒有video的部分。
「什麼?!那我們該怎麼辦?」
參考王選仲(GoatWang)大大在2018年鐵人賽的這一篇文章,我們認識了selenium。
於是我們就開始動手啦~
from selenium import webdriver
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome('./chromedriver')
driver.get("https://video.nationalgeographic.com/video/science/101-videos/0000016c-6e06-d99d-af7c-6e7749960000")
time.sleep(40)
html = driver.page_source
soup = BeautifulSoup(html,'html.parser')
video=soup.find('video')
print(video['src'])
driver.close()
這之中其實我還是遇到過一個問題──那就是webdriver。
我們雖然擁有chrome,但是他卻讀不到,而我這個人懶得去找他到底在哪裡,所以就直接上網下載了。
下載網址
這裡一定要選與自己的chrome版本相同的driver,我當時因為沒細看,就直接依照往例下載最新版,結果與我們chrome版本不符所以出錯。
想看自己chrome版本的話,直接載網址列輸入(chrome://settings/help)
這樣就可以看到了,同時也可以更新成最新版本。
然而因為我之前都有使用ADBlock,所以其實我以前根本沒遇過看此網頁需要看廣告這回事。所以設定3秒,我發現跑出來的網址是廣告時……
「啊啊啊……」感覺有種烏鴉飛過的感覺
最後一個乾脆設為40秒,我就不信一個廣告超過40秒!
然後就爬到我們要的網址啦!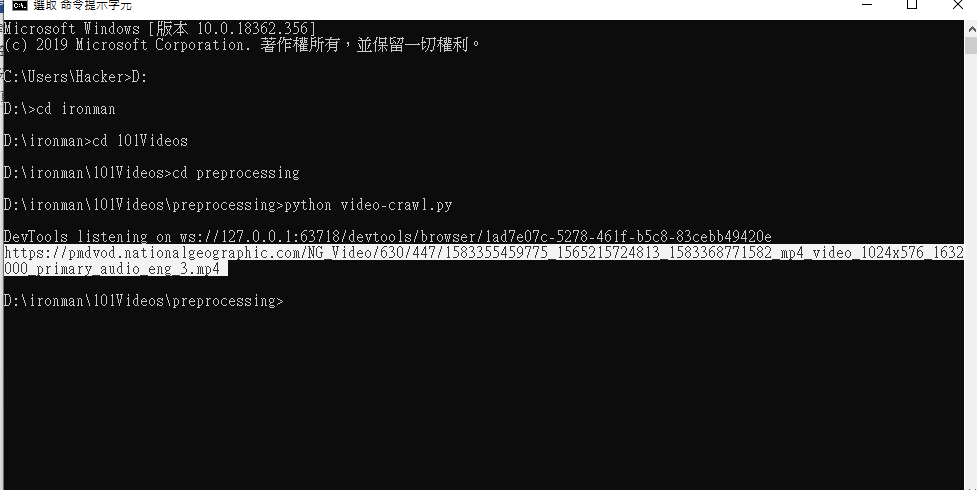
接下來就只需要用for來跑然後拿個json檔存取我們影片網址的位置就好了~
同時可以一起抓取影片預覽圖喔~^w^
明天我們要幹一場大事!
大家明天見~

